
Today at its I/O conference, Google unveiled Gemini 3.5, its latest family of AI models, along with Gemini Omni, a new model that can create video from any input.
The first available model in the Gemini 3.5 family is Gemini 3.5 Flash. This is now out for everyone via the Gemini app and it’s also available in AI Mode in Google Search. This model “delivers intelligence that rivals large flagship models on multiple dimensions, at the speeds you have come to expect from the Flash series”, Google says.
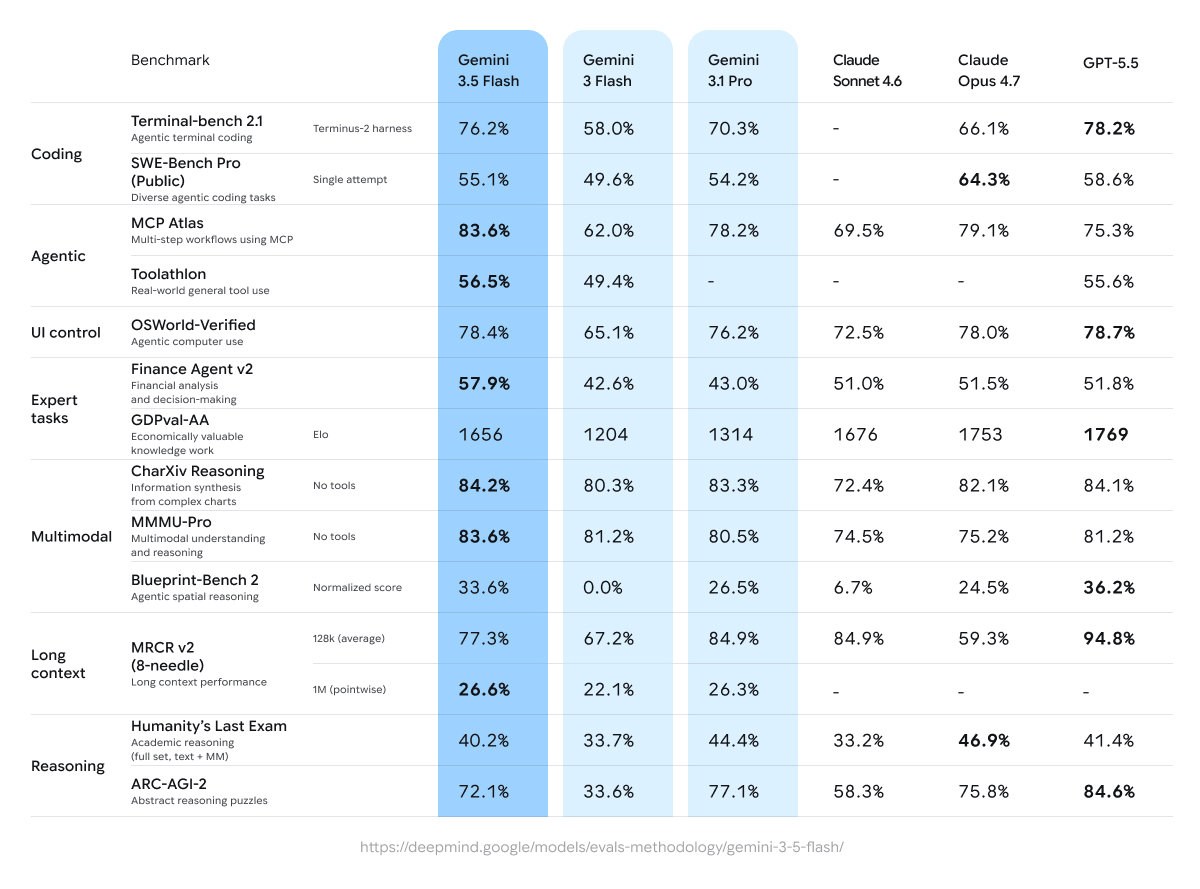

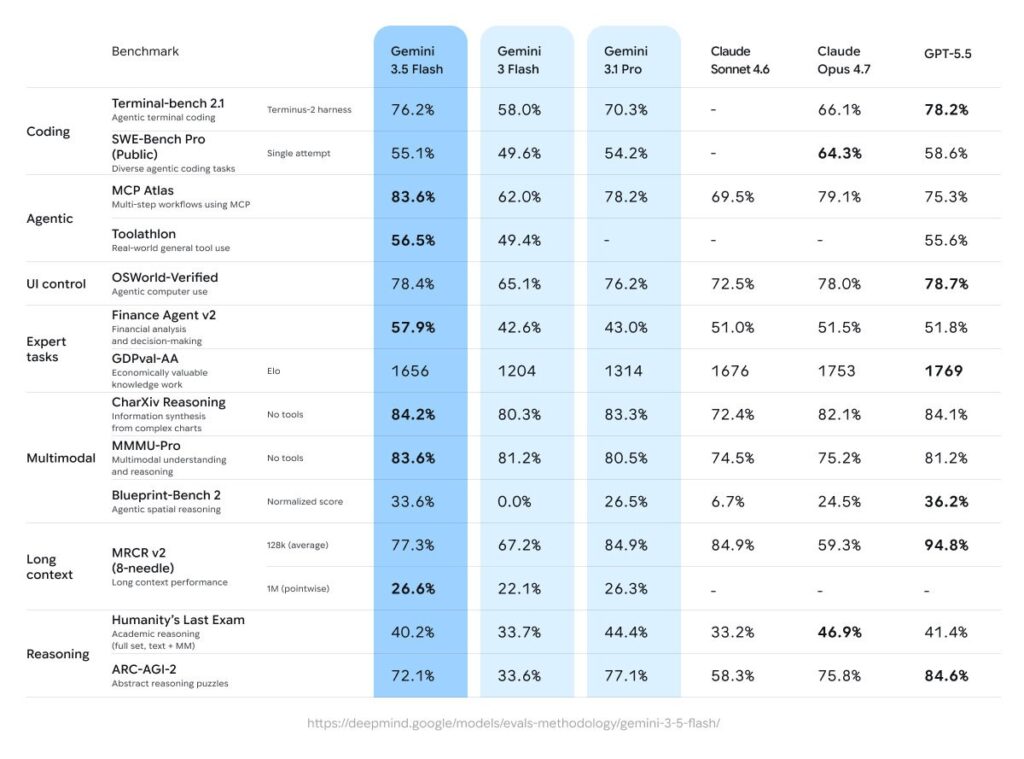
It’s the strongest agentic and coding Gemini model, outperforming even Gemini 3.1 Pro on challenging coding and agentic benchmarks, while leading in multimodal understanding. Gemini 3.5 Flash is now the default model.
Gemini Omni is a new model that can create videos from any input. You can combine images, audio, video, and text as input and it will generate high-quality videos “grounded in Gemini’s real-world knowledge”. Once a video is created, it can also easily be edited through conversation.

The first model in the Gemini Omni family is Gemini Omni Flash, which lets you change specific things about a video, or everything, and you can refine the creations across multiple turns, changing things without ever losing the thread of the original scene.
The model has “an improved intuitive understanding of forces like gravity, kinetic energy and fluid dynamics”, so it can create more realistic scenes. With Omni you can use your own voice and Avatars, which create a digital version of yourself. All of the videos include SynthID digital watermarking.
Gemini Omni Flash is available today for all subscribers to Google AI Plus, Pro, and Ultra plans globally in the Gemini app and in Google Flow. It’s also rolling out for free to users on YouTube Shorts and YouTube Create.